Shingoの数学ノート
プログラミングと機械学習のメモ
BERTを使ってみよう1
日付: カテゴリ: 自然言語処理
今回と次回で、BERTの理論と実装について紹介したいと思います。
今回は、実装のときに必要になるであろうBERTの理論を説明していきます。
BERTの雰囲気をつかめれば良いかなと思います。
基本的には、BERTの元論文と Attention Is All You Need、 BERTの実装コードなどを元に解説していきますので、 詳細を知りたい方はこちらを参考にしてください。(これらの論文の図を多用しています。)
BERTの概要
BERT(Bidirectional Encoder Representations from Transformers)は、言語表現を事前に学習するための新しい手法であり、様々な自然言語処理(NLP)タスクにおいて当時の最先端(SotA)の結果を得ています。
大規模なテキストコーパス(Wikipedia など)で汎用的な「言語理解」モデルを訓練し、そのモデルを気になる下流の NLP タスク(質問応答など)に使用します。
BERTは、NLPを事前に訓練するための初の教師なしの深い双方向システムです。
(参考:https://github.com/google-research/bert)
BERTの特徴をまとめると、以下のようになります。
- BERTは当時様々なタスクでSotAを更新したモデルである。
- BERTは事前学習済みモデルであり、汎用的なモデルである。
- BERTはWikipedia等の巨大なコーパスから教師なし学習で作成される。
- BERTは文脈を双方向に学習するモデルである
BERTの事前学習
BERTは事前学習済みモデルであり、事前学習で何を行うかが重要です。
BERTでは事前学習で手間をかけないよう、教師なし学習で事前学習を行います。
教師なし学習にすることで、大量のテキストデータさえあれば 人手でアノテーションを行うことなく学習をすることが可能となります。
BERTでは以下の2つのタスクを解きます。
- マスクされた単語の予測(MLM)
- 次文予測(NSP)
ちなみに、トレーニング前のコーパスは以下を使用しています。
- BooksCorpus(800Mワード)(Zhu et al. 2015)
- 英語版ウィキペディア(2,500Mワード)
マスクされた単語の予測(MLM)
教師なし学習タスクの1つ目は、「マスクされた単語の予測(MLM)」です。
MLMはある単語をMASKさせて、周辺の単語からMASKした単語を予測する穴埋め問題です。
全体の15%の単語をマスクし、残りの単語の並びからマスクされた単語を予測します。
また、 pre-trainingで[MASK]トークンは使用しないため、選択された全ての単語を マスクするのではなく、マスクされた単語を以下のルールで置き換えます。

次文予測(NSP)
教師なし学習タスクの2つ目は、「次文予測(NSP)」です。
質問応答(QA)や自然言語推論(NLI)などのタスクは、2つの文の関係を理解することが必要です。
文の関係性を理解するモデルをトレーニングするために、 単語コーパスから生成できる、2値化された次文予測タスクの事前学習を行います。
具体的には、以下のように学習データを作成し、次文予測を行います。
- 50%でBがAの後に続く実際の次文(としてラベル付け)
- 50%がコーパスからのランダムな文(としてラベル付け)

BERTの構造
例えば感情分析の場合、BERTの全体像は以下のようになります。
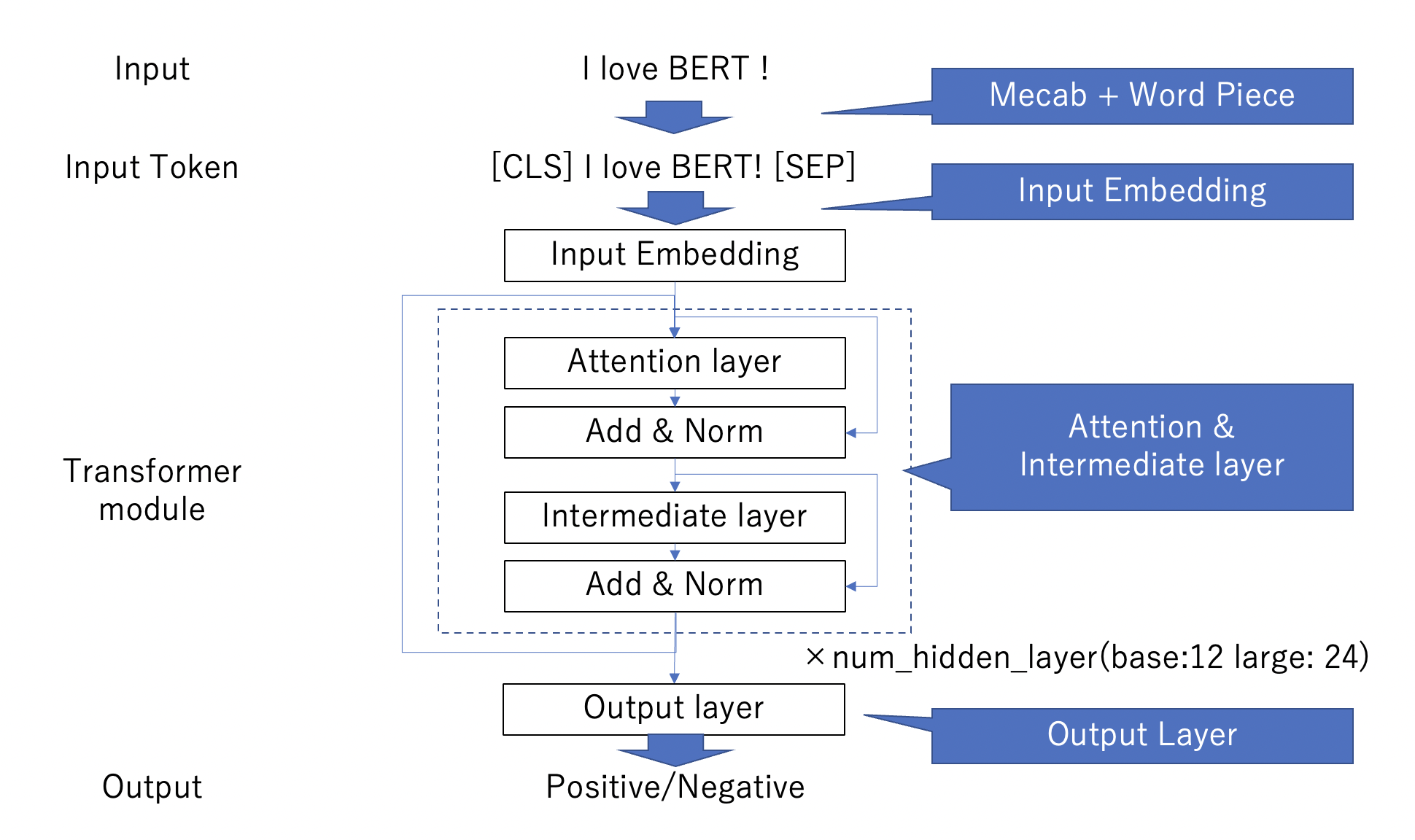
流れとしては、分かち書き(MeCab + Word Piece)から、Input Embeddingを経て、tranformer moduleをnum_hidden_layerの数だけぐるぐるします。 最後に、Output layerを経て出力します。
上から順にみていきましょう。
MeCab + Word Piece
入力の際に分かち書きをする際、通常の形態素解析器やスペース区切り等で作成した場合、 語彙数が非常に大きくなります。
そこで、BERTではWord Pieceというサブワード化手法を使用して語彙数を減らします。 これは、単語の中でさらに細かく分割し、高頻度の単語は1トークンとして扱い、 低頻度の単語はさらに細かく分割します。
例えば、BERTの日本語学習済みモデル(cl-tohoku/bert-base-japanese-whole-word-masking)のWord Pieceで分割してみます。 (日本語版BERTの単語の分割はMeCabを使用しています。)

カーネーションという単語が「カーネ」と「ーション」で分割されています。 このように、BERTでは語彙が登録されていない長い単語を短く区切ります。
Input Embedding
BERTでは、Inputの先頭に[CLS]トークンを、文の終わりに[SEP]トークンを追加します。
また、Input Embeddingでは以下の3つのEmbeddingを作成し、足し合わせます。
- Token Embedding
- Segment Embedding
- Position Embedding
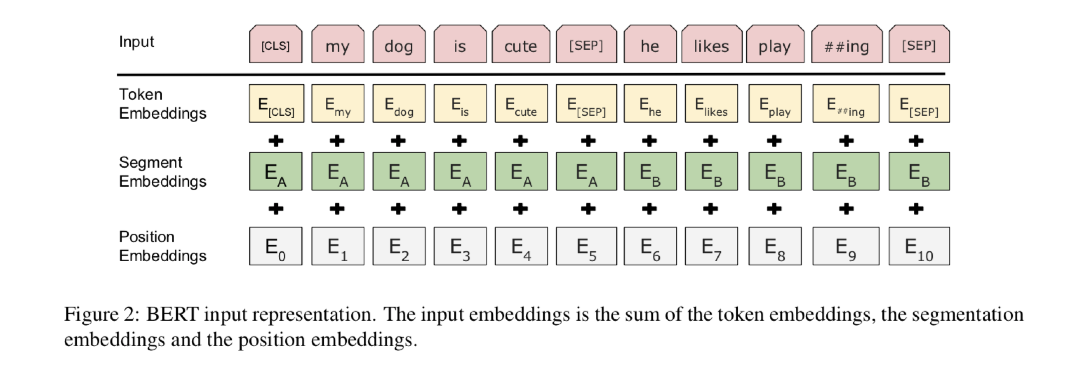
それぞれについて解説していきます。
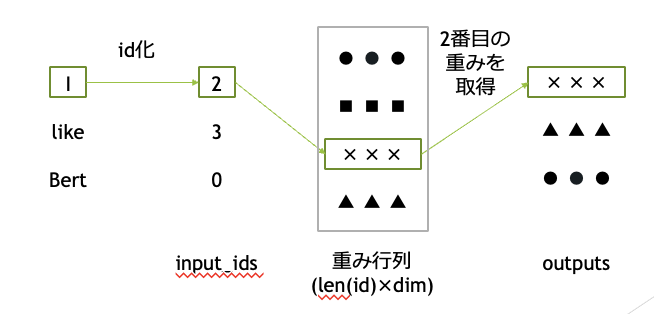
Token Embedding
Token Embeddingでは、Tokenのidから特徴量を作成します。
実際の計算では、one-hot-encodingしてから重みを掛ける処理を行います (この層の仕組みを一般にEmbedding Layerと呼びます。)
Segment Embedding
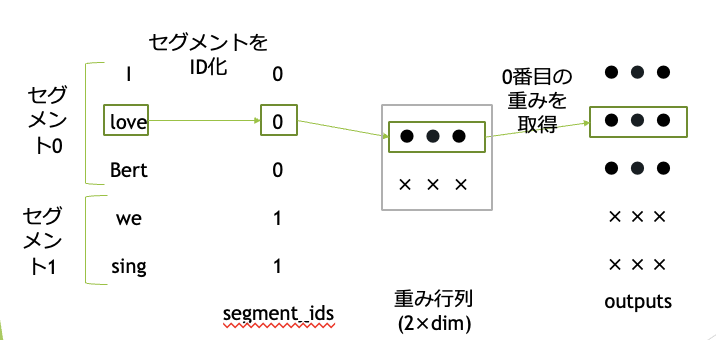
Segment Embeddingでは、文章のセグメントを0か1で入力します。
感情分析のように、文章を分けなくても良い場合は全て0を入力します。
Positional Embedding
Positional Embeddingでは、単語の順番を0から順に入力します。
これにより単語がどの位置にあるかを識別できるようにします。
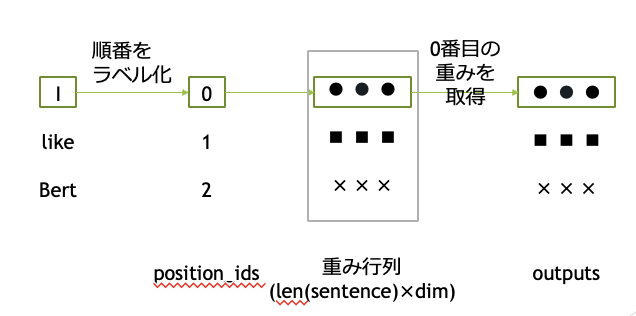
実装で入力する際は、TokenのidとSegmentのidを入力することになります。(Positional Embeddingは内部で処理をしてくれます。)
Attention Layer
BERTの肝であるAttention Layerをみていきましょう
BERTで使用されているのはScaled Dot-Product Attentionです。
Q(Query), K(Key), V(Value)の3つの行列を使用して、トークン同士の影響度を考慮します。
Attention Layerを挟むことにより、同じ単語でも文章によって異なる特徴量を算出できます。
では、全て同一のInputから全結合を通してQ,K,Vを生成する。(Self Attentionという。)
公式の図は以下の通りです。
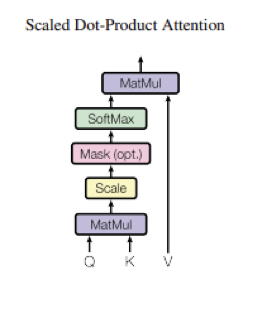
式で書くと以下になります。
ただし、$Q, K, V$は全て(単語数×隠れ層の次元数)の行列
さて、一つずつ解説していきましょう。
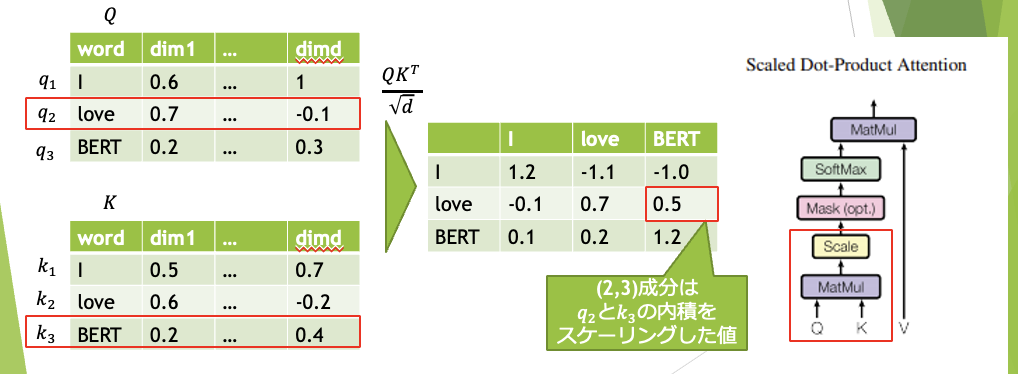
まずは、MatMulとScaleの部分です。簡単に言えば、QとKの内積を計算してスケーリング することで、QとKの類似度を算出しているようなイメージです。
なお、dim1…dimdは、d次元の特徴量を表しています。(BERT baseではd=768)
次に、Softmaxの部分です。
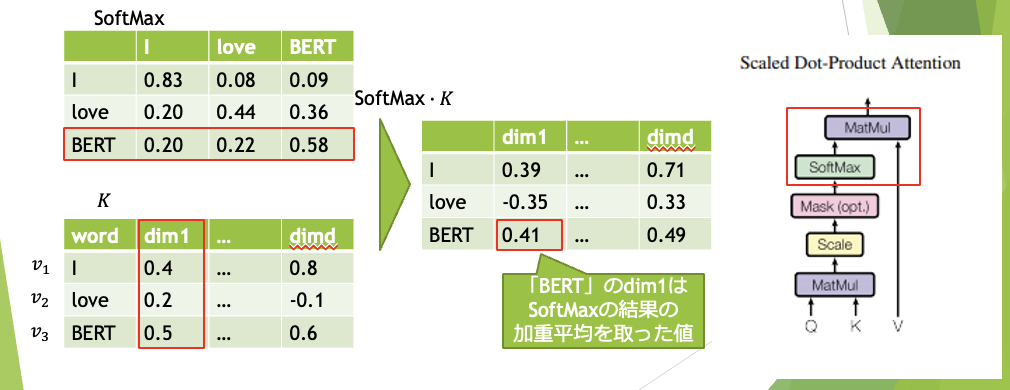
これは横方向にsoftmaxを取ることで、横を足し合わせて1になるように正規化しています。
この行列から、各トークンの、周辺のトークンによる重みを可視化することができます。

実装時、MASKは入力として与える必要があります。
最後に、SoftmaxとVのMatMulです。
これは前述のSoftmaxを使って、Vの加重平均を出しています。
つまり、Attentionでは周辺のトークンの重みを考慮して、特徴量を生成していることになります。
これにより、同じトークンでも文章によって異なった特徴量を生成することが可能です。
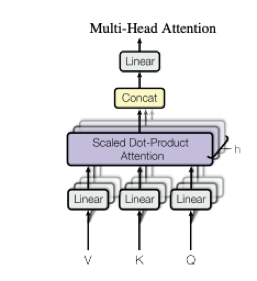
Multi-Head Attention
BERTでは、1つのAttentionではなく、特徴量の次元をh等分して複数のAttention Layerを 生成しています。これをMulti-Head Attentionと呼びます。(BERT-baseでは768次元を12等分しています。)
これにより、メモリの消費量も少なくなり、高速化も見込めます。
Intermediate Layer
Intermediate LayerはFeed Forword Networkとも呼ばれ、トークンごとに全結合を行う層です。
BERT baseでは、768次元を3072次元まで広げた後に、また768次元に戻しています。
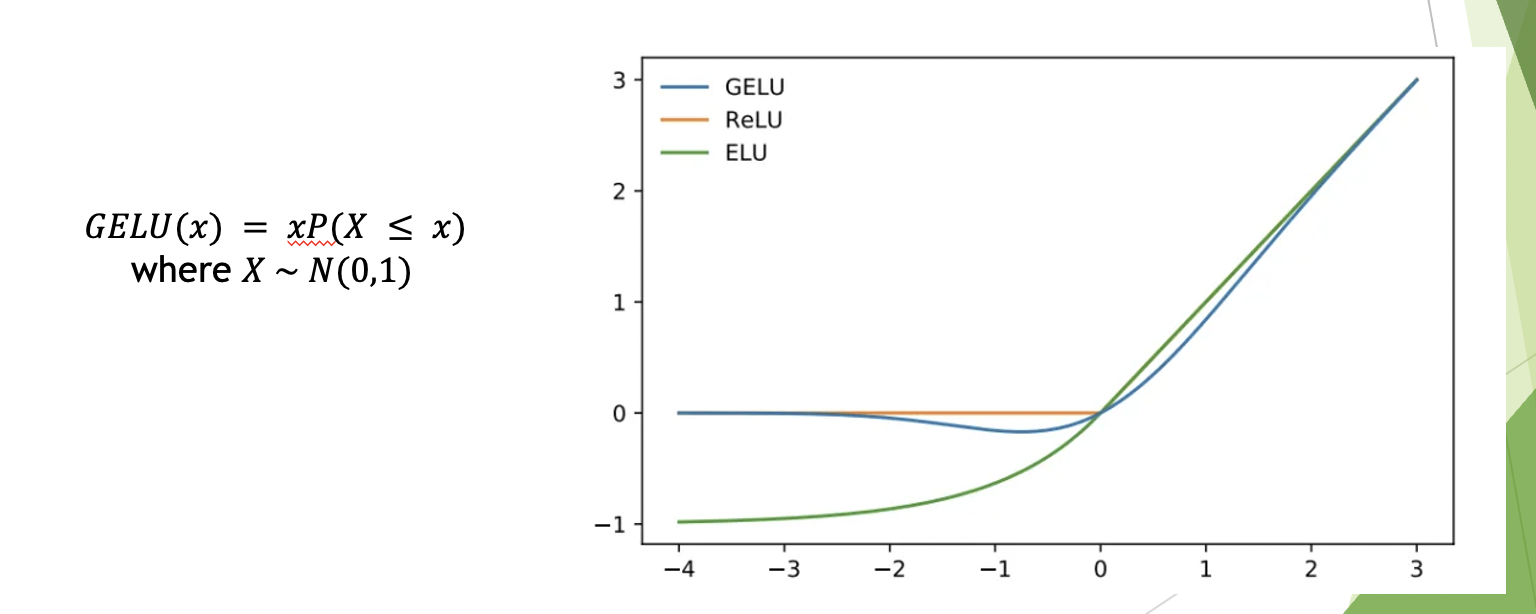
BERTのIntermediate Layerでは活性化関数にgeluを用いています。
geluはreluに近い関数ですが、0付近で滑らかになっていて、実数全体で微分可能です。
Output Layer
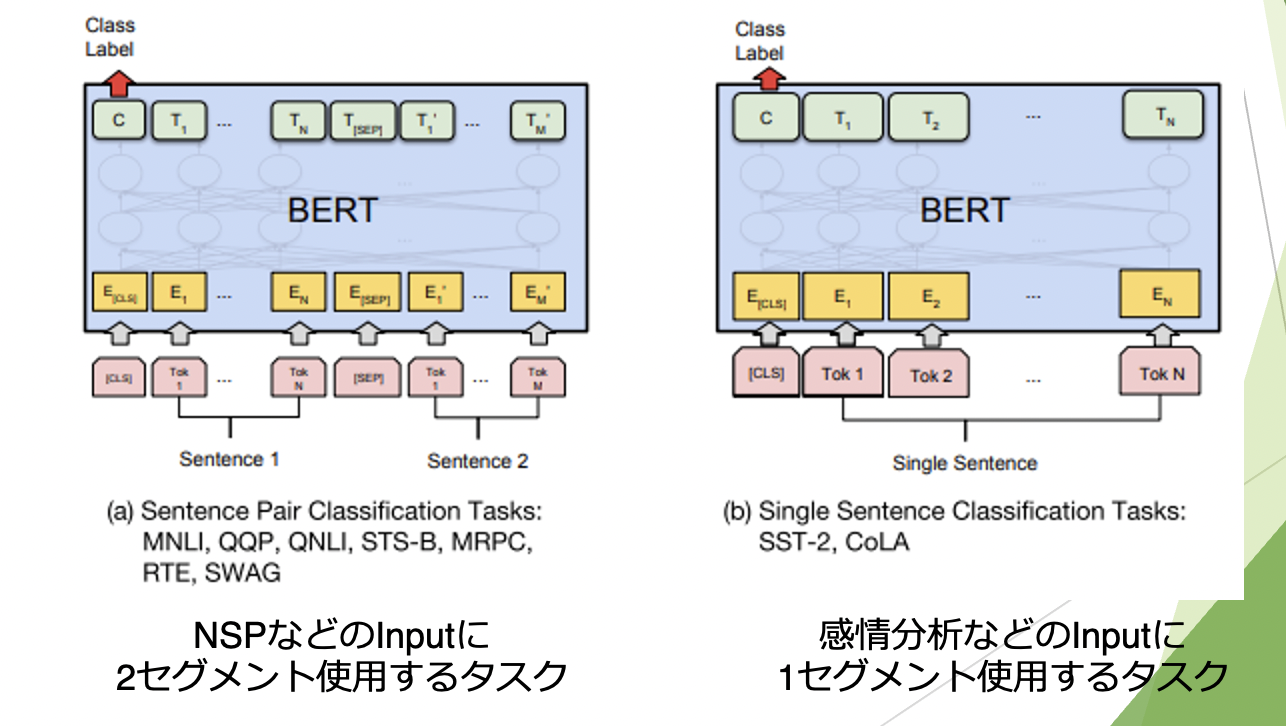
Output layerはタスクによって異なります。
次文予測(NSP)や感情分析等の文章ごとのクラス分類では、 [CLS]トークンの特徴量を使用して全結合を行います。
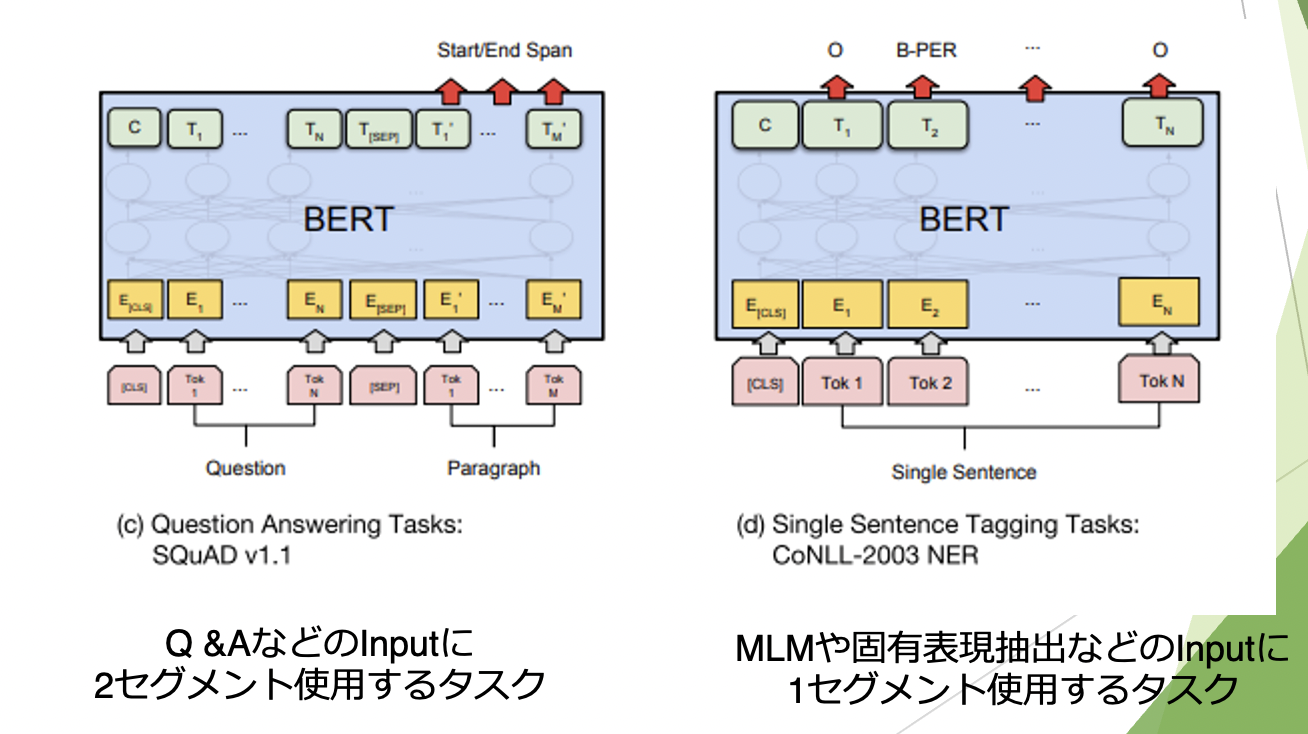
マスクされた単語予測(MLM)やQA、固有表現抽出などの単語ごとに出力する場合は、 トークンごと全結合を行い結果を出力します。
まとめ
BERTの実装のための理解にあたって、必要な箇所をまとめました。
ブログに書ききれていない部分も多々あると思いますが、BERTに関する素晴らしい論文やブログなどはたくさんありますのでぜひ他も調べてみてください。
この次のブログで、実装コードを紹介していく予定です。
参考文献
- BERT・XLNet に学ぶ、言語処理における事前学習 lib-arts 著
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova著
- Attention Is All You Need. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin著
- A Multiscale Visualization of Attention in the Transformer Model. Jesse Vig著
- GELU activation
- つくりながら学ぶ! PyTorchによる発展ディープラーニング 小川雄太郎 著