Shingoの数学ノート
プログラミングと機械学習のメモ
Pandasの処理を高速化しよう
日付: カテゴリ: SAS
最近KaggleやSignateを行う際、実行速度がタスクになっていることが多い気がします。
業務でも、大量のデータを処理する際に実行速度は問題視されることが多いです。
以下では、ここ最近で学んだPandasの高速化処理を紹介します。
実行コードはこちら
Polarsを使用する
まずはPolarsです。PolarsはRust製で高速な処理が実現可能であり、適宜並列化も行ってくれるそうです。
また、Pandasと同等の処理を書くことができるかつ、圧倒的に速いです。(下記の例では半分以下の時間で実行できている!)

Polarsについて覚える必要がありますが、sqlや、Rのdplyrみたいな感じで書けるので、慣れれば書きやすいです。
業務ではPolarsを使う人が多くないのでPandasで書いていますが、 コンペなどでは処理速度向上のためpolarsを使っています。
並列化手法を使用する
PandasやPolarsのメソッドに実装されていないような複雑な処理でも、 並列化できる処理(特にgroup処理など)は、高速で実行することができます。
並列化手法のうち、おすすめなものを紹介します。
- Pandarallel
- Joblib
pandasのapply処理を並列化してくれます。簡単に実装でき、progress barまで出してくれるのでありがたい。
listの内包表記を並列化する。進捗をテキストで表示できる。幅が広い。
以下は通常、pandarallel、Joblibそれぞれで実行したときの時間です。
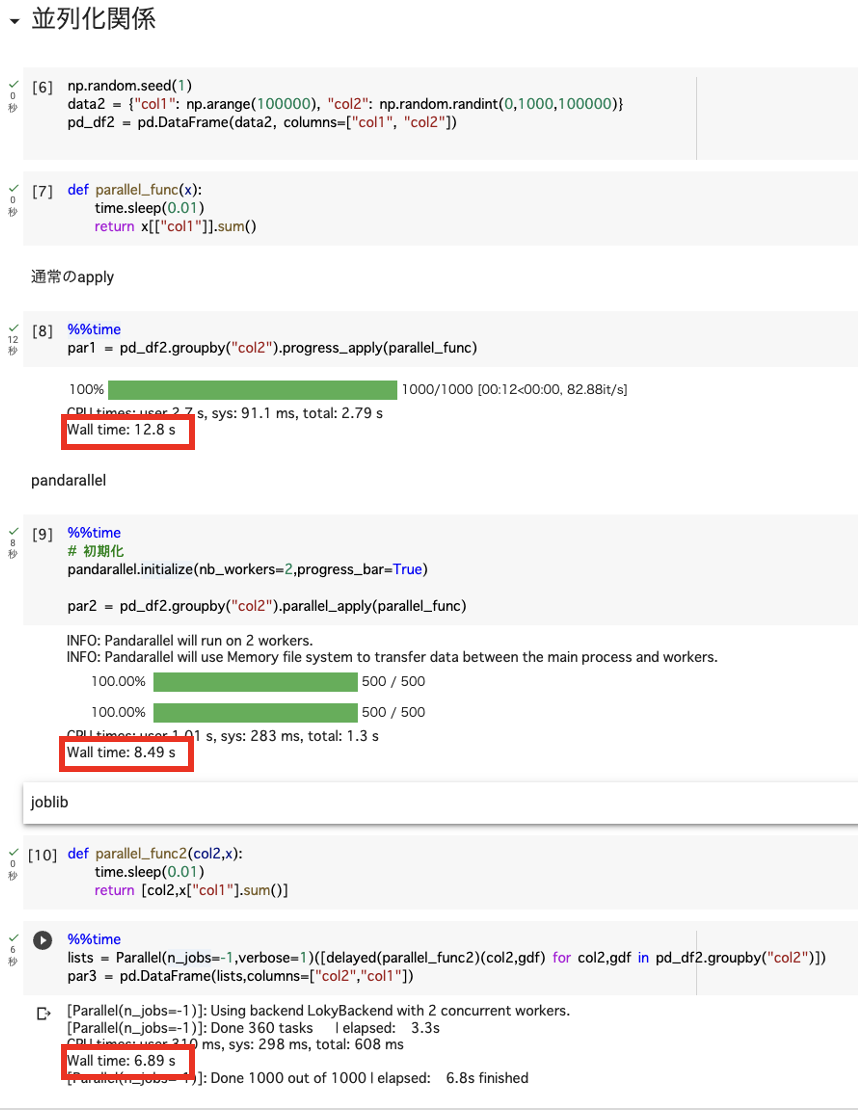
処理はJoblibを少し変えていますが、ほぼ同じ処理です(0.01s待って集計する処理)
Google Colabで実装しているため、2workerしか使っていませんが、それでもかなり早くなります。 Colab以外でworkerが多いPCで実行すればもっと早くなりそうです。
JoblibとpandarallelはJoblibの方が速そうですが、処理が多くなった時はどうかわかりません。 pandarallelは簡単にかけて可読性もよく、結果も見やすいので最近はpandarallelを使用してます。
まとめ
高速化できれば、時間が短縮できてより色々な手法が試せるようになります。 処理早いので業務でもPolarsがStandardになってくれないかなぁ(願望)