線形回帰分析と最尤推定法
はじめに
先日のブログで説明しましたが、最尤推定法は機械学習で多く使用されるパラメータ推定法です。
月並みではありますが、今回は、線形回帰分析のパラメータを最尤推定法で解いてみたいと思います。
線形回帰分析
まずは、線形回帰分析の定義を行います。 を目的変数、を説明変数とすると、線形回帰分析の式は以下のように表されます。
ただし、で、独立同分布を仮定します。(は、平均0、分散の正規分布にしたがっていることを表します。)
これにより、説明変数を定数だとみなすと、は、 で、独立な確率変数と見なすことができます。(正確にいうと、で条件づけたの条件付き確率を考えています。)
線形回帰分析と最尤推定法
さて、の確率分布が決まったので、尤度関数を考えてみましょう。
その前に、最尤推定法のおさらいです。
最尤推定法は、「パラメータをいろいろ変えて今あるデータである確率密度関数の値を出してみて、最も高いものをもとのパラメータとしよう」という考えのもと推定していきます。当然パラメータは無限の可能性がありいちいち代入していられないので、パラメータを変数とみた関数を考え、これが最大となるパラメータを最尤推定値とします。このパラメータを変数とみた関数を尤度関数といいます。
ということなので確率密度関数を出しましょう。
パラメータは、偏回帰係数のと、正規分布の分散です。
対数尤度関数を考えると、
ここで、を求めることを考えると、対数尤度関数を最大化するには、以下の式を最小化すれば良いことがわかります。
これ、実は最小二乗法と式が同じです。つまり、最小二乗法は、最尤推定法の観点からも妥当なパラメータ推定方法であることがわかります。
最尤推定値を求めてみる
一応を最小化するも求めておきます。
基本は、全てのについてをで偏微分して0となるを求めます。ちゃんとやるなら、「偏微分=0」だけでは最小値とは言えず、Eの凸性を議論する必要があります。(下記の「凸関数の最小化」が参考になります。)
http://www2.econ.tohoku.ac.jp/~ksuzuki/teaching/2005/ch5.pdf
ここでは、この証明は省きます。(感覚的にははに対して2次の多項式で、2次の多項式はは凸関数となるため、凸性を持つことが想像できます。ヘッセ行列を計算してみてもいいでしょう。)
さて、一つずつで偏微分するのは面倒臭いので、、、として、一気に計算します。
であり、以下の1.2の公式を使用すると、以下となります。
https://qiita.com/AnchorBlues/items/8fe2483a3a72676eb96d
したがって、以下が導けます。
これで線形回帰の解析解が求められました。
Pythonによる線形回帰
本当に一致するの?と疑問に思う人もいるかもしれないので、実際に計算してみましょう。
pythonのモジュール(statsmodels使用)
import pandas as pd
from sklearn.datasets import load_boston
import statsmodels.api as sm
#「boston house price」というデータをロード
boston = load_boston()
df = pd.DataFrame(boston.data, columns=boston.feature_names)
df['PRICE'] = boston.target
# 変数「CRIM」から「LSTAT」を説明変数として、「PRICE」を予測する
X = df.drop('PRICE', 1)
y = boston.target
# add_constantで定数項を挿入
model = sm.OLS(y, sm.add_constant(X))
result = model.fit()
result.summary()
結果:
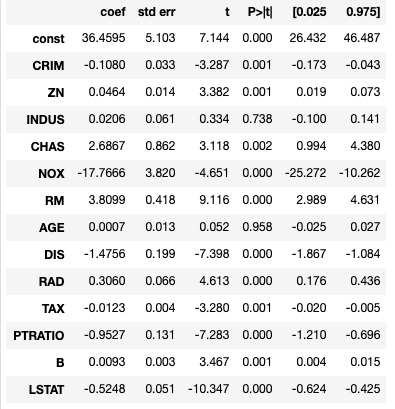
numpyで先ほど求めた解析解を計算
import numpy as np
X_add = np.array(sm.add_constant(X))
beta = np.linalg.inv((X_add.T @ X_add)) @ X_add.T @ y
pd.Series(beta, index=sm.add_constant(X).columns)
結果:
const 36.459488
CRIM -0.108011
ZN 0.046420
INDUS 0.020559
CHAS 2.686734
NOX -17.766611
RM 3.809865
AGE 0.000692
DIS -1.475567
RAD 0.306049
TAX -0.012335
PTRATIO -0.952747
B 0.009312
LSTAT -0.524758
dtype: float64
coefの部分の結果は一致していますね。
線形回帰のパラメータ推定値の性質
最尤推定値の統計的性質より、一致性と漸近正規性を持ちます。昔のブログで書いた線形回帰分析のパラメータが一致性を持つというのは、パラメータが最尤推定値であることからも証明することができます。
まとめ
線形回帰分析において、最尤推定法によるパラメータ推定と最小二乗法によるパラメータ推定は同じ結果になることがわかります。最小二乗法は最尤推定法の観点からも妥当な推定法であると言えます。
他のポアソン回帰やロジスティック回帰等の一般線形回帰分析も最尤推定法が元になっています。これについても記事をかけたらなと思います。
Comments
Loading comments...