Shingoの数学ノート
プログラミングと機械学習のメモ
マッチしないデータの要因を決定木で特定する
日付: カテゴリ: データ分析
今回は業務中に思いついたネタで、想定読者はどちらかというとデータエンジニアです。
分析をしたことがない人にも読めるように書きましたので、ぜひ見てください!
データがマッチしない要因の特定
さて、データエンジニアなら、別システムから出された2つのデータがどれだけマッチしているか、マッチしていなければその要因を調べることってありますよね。
そのデータの出力方法などよく知っていれば良いのですが、よく知らないデータを検証することもあります。
また、変数名もバラバラだったり、入っている値がズレてたりして、完全一致で要因探索ができない場合もよくあります。
一つ一つ変数を見ていけばわかるかもしれませんが、何百もの変数があるときは結構大変です。
決定木とは
ここで、データ分析手法の一つである決定木分析の登場です。
分析手法を聞くと、「データ分析者の仕事」とか、「難しいアルゴリズムで予測」とか思い浮かべるかもしれませんが、 私は探索的データ分析や、エラーの要因特定でも決定木のような分析手法を使っていくと楽になる場合があるんじゃないかと思っています。
(自分はちょっとしたことでも実際に決定木を描いて要因分析したりしてます)
さて、決定木分析を大雑把にいうと、ある変数が高いか低いかで分岐を作成してグループ分けします。 これを何度も繰り返して最終的に0か1かを予測していく分析手法です。
分岐の仕方は、決定木側で決めてくれます。
実際に見るのが早いので、試してみましょう
データの差異の要因分析の設定
今回は以下の想定のもと、データの差異の要因を求めていきます。
- 同じデータだが、システムの違う2つのデータ(df1、df2)があり、金額に差異があるため、何が原因で差異が起きているのか調べたい。
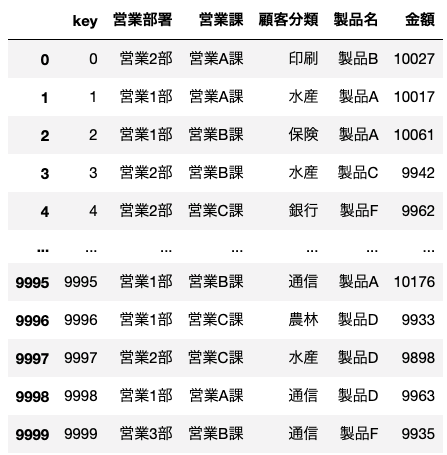
- df1の変数はkey、営業部署、営業課、顧客分類、製品名、金額であり、df2の変数はkeyと金額のみである。
左がdf1、右がdf2です。

差異は以下のように作成しました。
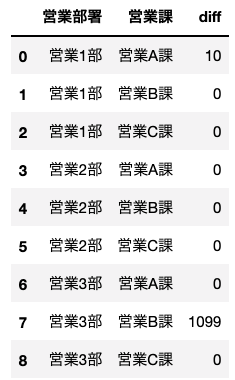
- 営業3部、営業B課の売り上げがdf1とdf2で全て違う
- 営業1部、営業A課のdf2のデータが一部存在しない
実際に、df1とdf2で結合したデータの差異(diff)の数は以下の通りです
もちろん部と課に要因がありそうとわかっていれば簡単に原因が突き止められますが、 データについてよく知らなかったり、データが複雑で何個も変数があり、色々な組み合わせでどれが要因となっているか検討がつかない状態で これを探すのは大変です。
決定木で要因分析
では、実際に決定木で探してみましょう。
コードはgithubで公開していますので、そちらも合わせてご覧ください。
https://github.com/Shingo425/DataAnalysis/blob/main/src/DecisionTreeForUnmatch.ipynb1.決定木に使用する変数の決定
まず第一に、決定木に使用する変数を決めます。
数値変数、カテゴリ変数どちらでも大丈夫ですが、 あまり多いカテゴリだと解釈が難しくなるので、 ある程度大きいまとまりのカテゴリ変数を使用すると良いです。 今回はkey以外の営業部署、営業課、顧客分類、製品名、金額を使用します。
2.カテゴリ変数の数値化
Pythonのsklearnの決定木は、全て数値じゃないと動いてくれません。 従って、カテゴリ変数にOne-Hot-Encodingを適用します。 (カテゴリを横に並べて、存在したかどうかを0と1で表します。)
できたデータはこんな感じです。
3.決定木の適用
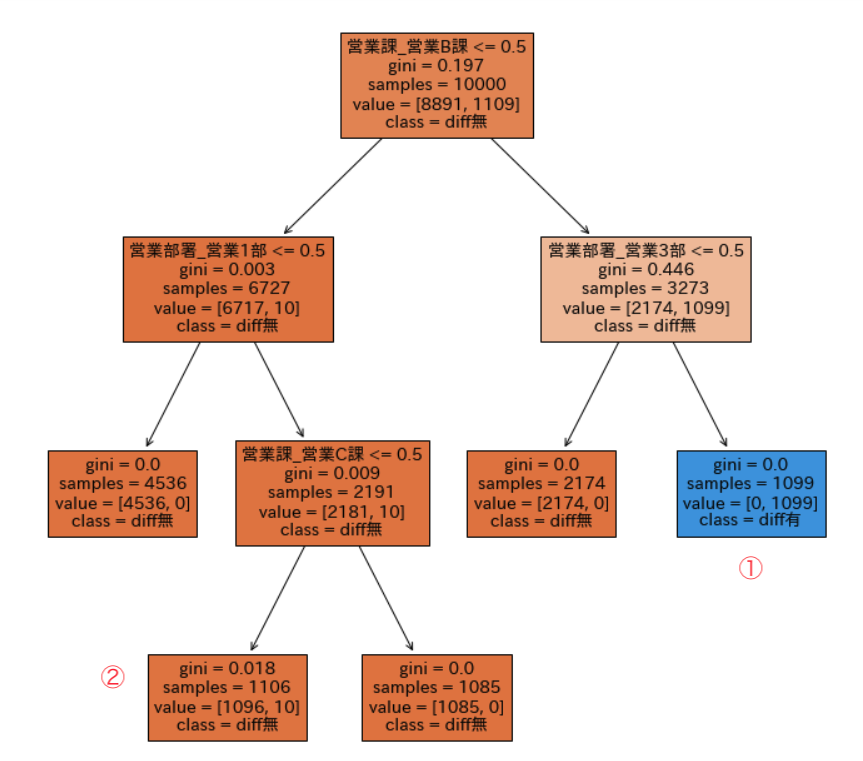
diffを目的変数、1で選んだ変数を特徴量として、決定木を回します。 決定木にはパラメータがいくつかあるのですが、とりあえず深さだけ3に設定しておきましょう。 決定木では、plot_treeで以下のように図を描いてくれます
4. 精度の確認
決定木がどれくらい分類できたのかをみましょう。

10件実際にはTrueなのに予測がFalseとなっている箇所がありますが、その他は正解しています。
このように精度が高ければ、何らかの原因でわかれていることがほとんどです。
ちなみに、この10件の原因は後で解説します。
5. 要因の探索
3の図は、Trueなら左、Falseなら右にたどって見ます。
また、各ノードのvalueは[diff=0の数,diff=1の数]を表します。
valueを確認すると、diffが存在する最終ノードは、①と②です。
①は全てdiffありで、カテゴリ変数は全部0と1で表されていることに注意すると、 「営業B課が1かつ、営業3部が1」、 つまり「営業B課かつ営業3部」のときに全て差異が出ていることがわかります。
②は10件diffありで、 「営業B課が0かつ、営業1部が1かつ、営業C課が0」、 営業の課はA,B,Cのみなので、「営業1部かつ営業A課」のときに10件差異が出ていることがわかります。
まとめ
差異の要因が完璧に導かれましたね。
5ステップで色々やってそうですが、実際のコードはかなり短いです。 (githubのnotebookを参照してください。)
このデータは差異がはっきりしているためきれいに出ますが、 実際きれいに出ないことも多いです。
そういうときでも、予測精度が高ければ、 決定木の上位の変数でわかれているかも?という推測が立つので、 その変数を重点的に調べていけばいいわけです。
終わりに
データ分析は複雑なアルゴリズムを使って何かすごいものを予測!というのを想像しがちですが、 身近なデータの探索に使う決定木も立派な分析手法ですし、とても大切だと思っています。
要因探索については、一つ一つデータやグラフを見ていくのももちろん大切ですが、 こんな感じで決定木を使ってみると、 もしかしたら業務がかなり効率的になるかもしれません。
ちょっとしたことで手軽に分析も楽しいですよ、という紹介でした。
余談 データ10件の予測ミスについて
さて、完璧に原因は突き止めたわけですが、10件予測が間違っています。
これは、決定木の予測確率は最終ノードの0と1の比率で決まるためです。
②の10件が入っているノードをみると、0が1096件あり、1の件数をはるかに上回ります。
従って、このノードの予測確率は10/(10+1096)となります。
また、決定木の予測ラベルは予測確率が0.5を超えるか否かなので、 このノードに入っている予測はdiffなしとなってしまうのです。
よく考えると、営業1部かつ営業A課はdiffなしの方が多いので、 ここをdiff有とするのは正解率はもっと下がりますね。