Shingoの数学ノート
プログラミングと機械学習のメモ
データサイエンティストの業務内容
日付: カテゴリ: データ分析
今回は、データサイエンティスト(以下DS)ってどんなことをしているのか書いていこうと思います。
もちろんDSといっても、扱うデータや種類によって全然違うので、あくまで一例として見ていただければと思います。
DSを目指している学生や、転職しようと思っている社会人に対して、DSってこんな仕事をしているということを知っていただきたいです。
DSってどんな職業?
まずは、DSについて知らない方もいると思うので、以下にDS協会による定義を載せます。
データサイエンティストとは、「データサイエンス力、データエンジニアリング力をベースにデータから価値を創出し、ビジネス課題に答えを出すプロフェッショナル」です。
ここでの「ビジネス」とは企業の営利活動だけではなく、社会の役に立つ意味のある活動全般を指します。「プロフェッショナル」とは、体系的にトレーニングされた専門的なスキルをベースに顧客(お客様、クライアント)に価値を提供し、その対価として報酬を得る人です。
上記の定義では、「ビジネス力」「データサイエンス力」「データエンジニアリング力」の3つのスキルが出ていますが、DSのスキルは以下のように定義しています。
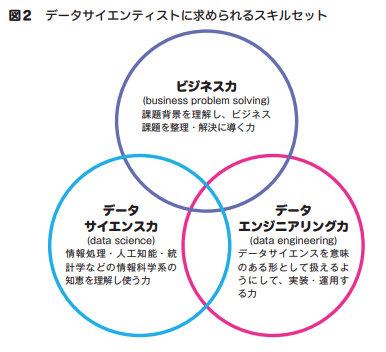
データサイエンティストの業務を遂行する上で、ビジネス力、データサイエンス力、データエンジニアリング力はどれも欠けてはいけないと思っています。
また、データサイエンティストは定義が広く、機械学習とアプリ実装をメインに行う人もいればビジネス課題の解決に注力する人もいます。
特に前者は機械学習エンジニアと呼ばれることもあります。このブログでは、後者の仕事をデータサイエンティストの仕事として書くことにします。
筆者の入社してからの経歴
私は現時点で、現在の会社に新卒として入社してから5年目になります。
1年SE/PGとしてデータ移行業務やシステム開発したのち、3年半DSとして働いています。
プロジェクトは1人から2人でやる案件が多く、期間は3ヶ月程度のものもあれば、2年近くやっていたものもあります。
以下では、今まで私がした経験や、DSに聞いた話などをまとめていきます。
DSの主な業務
DSの業務としては、まとめると以下の流れになることが多いかと思います。
フェーズによって、使用するであろうスキルで色分けしています。
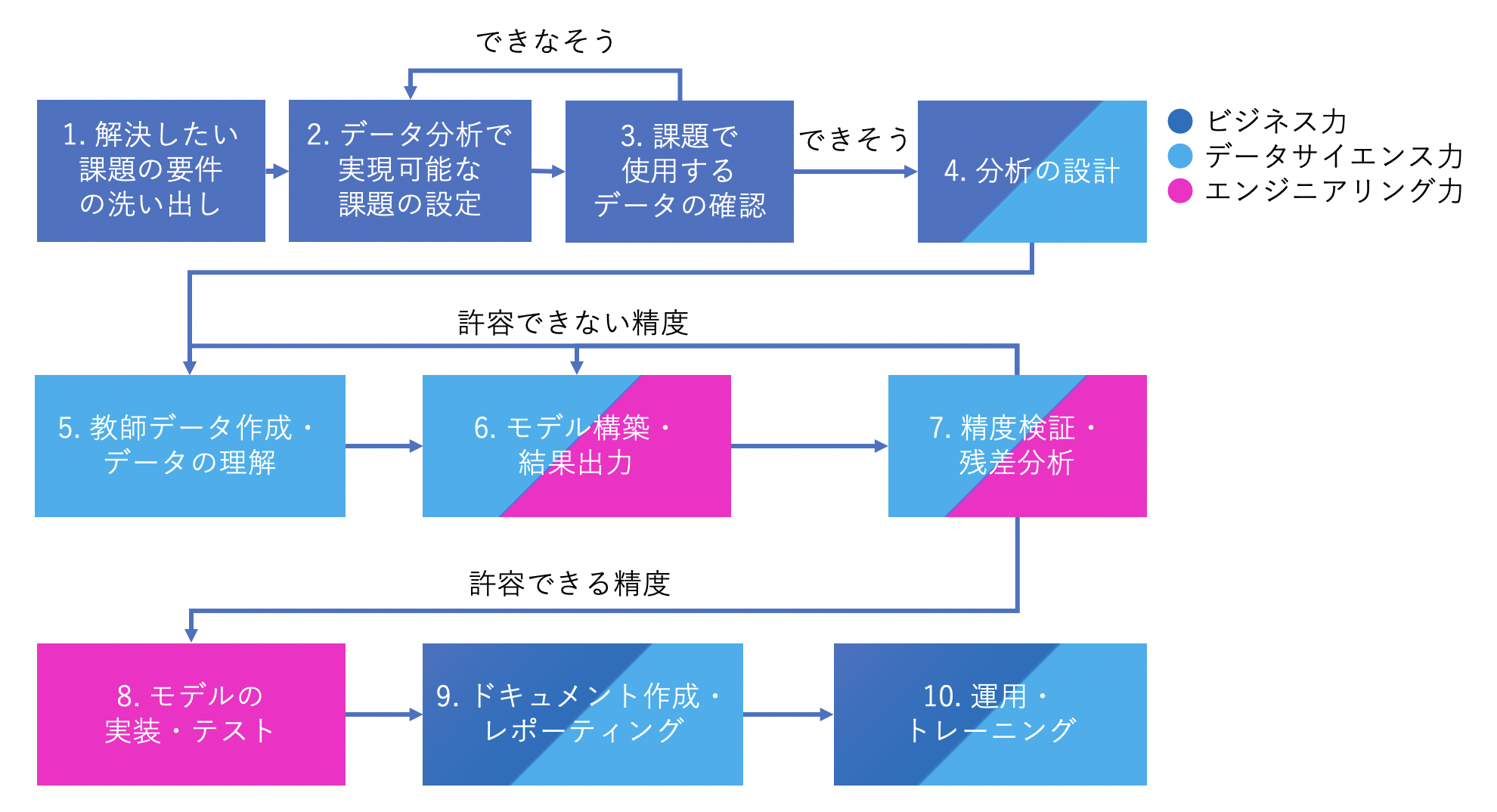
- 解決したい課題の要件の洗い出し
- データ分析で実現可能な課題の設定
- 課題で使用するデータの確認
- 分析の設計
- 教師データ作成・データの理解
- モデル構築・結果出力
- 精度検証・残差分析
- モデルの実装・テスト
- ドキュメント作成・レポーティング
- 運用・トレーニング
必要なスキル:ビジネス力
まずはお客さんの要件を聞いて、どんな課題があるのかを理解します。
まだデータは見ていないので、ここではざっくり課題を聞いて、何を求められているのかを把握します。
必要なスキル:ビジネス力
課題を聞いたのち、現在のデータでどのような課題を設定すれば、分析で実現可能かを検討します。
特に教師あり学習の場合、目的変数(予測対象の変数)と説明変数(予測に使用する変数)に使えそうなものを考えます。
例えば、課題で住宅の価格を予測したいとしたときは、目的変数に住宅価格を、 説明変数には価格に必要な土地の情報だったり、住居の基礎情報などを使用するわけですね。
こう聞くと、簡単かと思われがちですが、目的変数の設定が難しい場合も多々あります。
例えば、製薬業界で各薬品に対して、MRがどの医師にアプローチすれば良いかを考えます。
このとき、医師ごとの売上データを目的変数としたいですが、売上は施設粒度までしか出せない場合があり、その場合は医師ごとの売上を直接出すことはできません。
そこで、どうやって医師ごとの目的変数を定義するかを考えるわけです。
これはなかなか難しい問題で、存在するデータやビジネス課題によって、目的変数の定義が変わってきます。
何を予測対象とするのか、どんな粒度で予測するのか、顧客と色々話して決めていきます。
必要なスキル:ビジネス力
2で定義した目的変数、説明変数がちゃんと取れるかを確認します。
データが取得できるかだけでなく、いつ時点のデータが取れるかも重要です。
目的変数が説明変数に対してリーク(説明変数に目的変数の情報が入っていること)が起こってないか、 予測するタイミングで必要な変数が揃っているかなども考えます。
例えば、ある商品の売上予測で、営業が入力した顧客の活動回数を使用したいとします。
この情報は予測に対してよく効く変数ですが、営業担当者によって活動を入力していたりしていなかったりします。
そうすると、顧客によって情報の精度が違ってきたりするわけです。
さらに、反映タイミングもばらばらだとすると、その変数が本当に使用できるか吟味が必要になってきます。
もし、今あるデータで課題の解決が難しいようなら、2に戻って分析可能な課題を再定義します。
必要なスキル:ビジネス力・データサイエンス力
ここで、モデルの種類、評価方法、評価指標などを決めていきます。
コンペ経験者なら、例えばテーブルデータの分類問題であれば、大体モデルはlightgbmで、評価はクロスバリデーションのAUCすればいいんでしょ、 となるかもしれませんが、実際はそうでない場合もあります。
例えば、顧客が機械学習に詳しくない場合、AUCの数値を言われてもピンとこない場合があります。(実際AUCの説明も難しいです。)
その場合は、ホールドアウトの混同行列を用いて、適合率や再現率を提示したこともあります。
モデルに関しても、ただ精度を求めるだけでなく、線形回帰や決定木など、 どんな変数がどの程度効いているかをわかりやすくするために使用することもあります。
したがって、顧客に合わせて分析の設計をする必要があるわけですね。
必要なスキル:データサイエンス力
機械学習がすぐに適用できるようなデータになっていればよいのですが、なっていない場合もあります。
例えば各個人に対してクレジットカードのデフォルト予測などで、個人の履歴データがある場合です。
教師データが一つになっていない場合は、結合や変数の加工を実施して一つの教師データを作成していきます。
特に例のように、結合するデータの粒度が予測対象より細かい場合はうまく集計して特徴量を集計する必要があります。
例えば履歴データは1ヶ月前、2ヶ月前…の情報など、一人に対して複数のデータを持っている場合、予測対象は各個人なので、なんらかの形に集計しなければなりません。
よくあるのが、平均、合計、標準偏差、最大値、最小値などの統計値を全て入れることです。
ここら辺の、教師データを作成することに関しては以下のkaggleの課題がとても勉強になると思います。
https://www.kaggle.com/c/home-credit-default-risk/overview
課題とデータが決まれば、データを見ていきます。探索的データ分析(EDA)ですね。ここにきてようやくデータ分析っぽいプログラミングをします。
さて、教師データが作成できたら、集計値やグラフを書いてデータの概要を把握していきます。
ここで、データのパターンや欠損値や外れ値、異常値の有無などを発見します。
ここのデータ理解が、のちの精度や運用にとても大きく関わってくるので、念入りにEDAは実施します。
必要なスキル:データサイエンス力・データエンジニアリング力
データの理解が終わったところで、分析の設計で定義したモデルの構築を行っていきます。
この段階でコーディングを実施していきますが、のち変更前提で柔軟にモデルを構築できるよう、 うまく関数を定義して作成することを心がけます。
また、特徴量エンジニアリングやパラメータチューニングなどの精度向上の手法は基本的に後回しにして、 とにかく精度を出すまでの一連の流れを先に作成することが重要です。
なぜかというと、精度向上は終わりがほとんどないのに対して、 納期には時間があるためです。
モデル構築時にパラメータチューニングしたいのは山々ですが、 精度向上以外の部分のコーディングを終わらせてから精度向上に取り掛かるようにします。
必要なスキル:データサイエンス力・データエンジニアリング力
モデルを構築したあとは、分析の設計で決めた評価方法・評価指標で精度を検証します。
モデルの精度向上のために、精度はもちろん、 どの変数が効いているか、予測を外している原因は何かを突き止めます。
例えば、IDがモデルに入っていたとか、異常値が原因で、予測値がおかしくなっているなどです。
分析のコンペなどと違って、データによっては完全に予測できる変数などが 混じっている可能性(リーク)などが往々にしてあるので、本当に残差分析は重要です。
さらに、この部分は顧客にも説明する必要があるため、 さまざまな統計値、精度、グラフなどを出力する必要があります。
モデルの精度が許容できるものになるまで精度向上の試行錯誤を行います。
ただし、時間がそんなにあるわけでもないので、 ある程度できたら目標に達していなくても次のステップにいく場合もあります。
必要なスキル:データエンジニアリング力
モデルが構築できたら、入力、出力の形式やタイミングを決め、自動化できるようにします。
また、モデルが想定通りの結果になるかどうか、さまざまなデータを入れてみてテストも行います。
さらに、入力データに欠損が入る場合や、異常値が入る場合にもそれに対応した出力結果になるようにテストします。
実装にも種類があり、例えばアプリケーションにしてほしい、クラウドに実装して欲しいなど、 さまざまな要望が入ることがあり、エンジニアリング力が試されます。
必要なスキル:ビジネス力・データサイエンス力
最後に、モデルの設計書や手順書などをまとめたり、統計値や評価指標をレポーティングしたりします。
レポーティングでは分析の設計や、精度検証・残差分析で実施した内容を主に記載していくため、 この手順通り実施していけば、結果を貼り付けていくだけで完成します。
また、顧客のレベルに合わせて、統計値や評価指標の解説を入れることもあります。
必要なスキル:ビジネス力・データサイエンス力
ここは蛇足で別案件となる場合が多いですが、 作成したモデルを顧客に運用してもらえるように、トレーニングをする場合もあります。
ここで、モデルの使い方だけでなく、データ分析の基礎であるデータの見方だったり、モデルの解釈だったりも解説します。
案件の仕事の範囲
では、全ての案件でこの1から10を全て担当するかと言うと、そういうわけではありません。
例えば顧客にもDSがいて、人手が足りないと言う理由でコーディングの部分(5から9)のみを担当することもあったりします。
また、上記の業務を全て一人で担当するわけでもなく、チームで分担して作業することもあります。
いきなり全てのフェーズで活躍するのは難しいので、自分の得意なスキルやフェーズを見つけつつ業務をしていくのが良いかと思います。
業務と分析コンペ
DSになるために、KaggleやSignateなどの分析コンペに取り組むことはとても重要です。
しかし注意したいのは、分析コンペで得られる知識は一部だということです。
上記の業務で言うと、5から7の部分が分析コンペと重なる部分です。
もちろんここがDSの目玉となる業務ですし、身につけておくととても役に立ちます。
しかし、ビジネス課題の発見・設定や、分析の設計、分析のわかりやすい説明・文書作成スキル、モデルの実装など、特にビジネス力・エンジニアリング力に関しては分析コンペでは補えない部分もあります。
この部分は実際に業務を経験するのが早いですが、 もし独学でやるなら、実際にアプリケーションを作成してみたり、 自分で気になったものを実際に分析し、ドキュメンテーションも作成しておくとかなり勉強になるのではないかと思います。
逆に言えば、Kaggleでいい成績を残せないからといってDSとして活躍できないかと言うことはなく、 ビジネス課題を見つける力、わかりやすく伝える力などがあれば十分DSとして活躍できると思います。
まあ、DSなら、せっかくKaggleやるなら上位狙いたいですけどね(笑)
おわりに
このブログでは、DSの業務内容について、一般化した形で紹介してきました。
これはあくまで私の経験によるものなので、必ずそうとはかぎらないことに注意してください。
DSの業務について理解していただいて、ぜひ就活、今後のDSとしてのキャリアなどの参考にしてください。