Shingoの数学ノート
プログラミングと機械学習のメモ
佐賀県は「九州の埼玉」なのか、機械学習を使って解いてみた
日付: カテゴリ: 自然言語処理
佐賀県は「九州の埼玉」?
ちょっと前、こんなニュースが回ってきました。
https://saga.keizai.biz/headline/1356/しかし、本当に佐賀は九州の埼玉なのか、Twitter上で話題になっているのを目にしました。
データサイエンティストたるもの、機械学習によってこれが本当なのか証明せざるを得ない。
ということで、Twitterから都道府県のツイートを取得し、各都道府県の類似度を計算してみました。
分析手法
具体的な方法は以下の通りです。
- Twitterから都道府県名が含まれるツイートを47都道府県で取得(上限10000件)。
- ニュース記事などのツイートを削除、@... やURL部分を消去。
- 形態素解析によって、都道府県名が地域のもののみを取得する。(大分、山口などの人の名前や日常で使われている文を弾く)
- 都道府県を塗りつぶし、これを教師データとする。
- 塗りつぶした都道府県を予測するモデル(BERT)を構築する。
- 各ツイートから都道府県の予測確率を算出し、正解の都道府県別に予測確率を平均し、その値を各都道府県の類似度とする。
(例) 北海道の海鮮丼は別格だ。 → ■の海鮮丼は別格だ。
(例) ■の海鮮丼は別格だ。 → 正解:北海道 として予測
(例) 北海道のツイートを予測
■の海鮮丼は別格だ。 → 予測確率 北海道:50%、青森:10%、...
■はうにやいくらで有名だ。 → 予測確率 北海道:40%、青森:10%、...
↓予測確率を平均
北海道の類似度→北海道:45%、青森:10%、…
実際にモデルに使用した都道府県ごとのツイート件数は以下のようになりました。
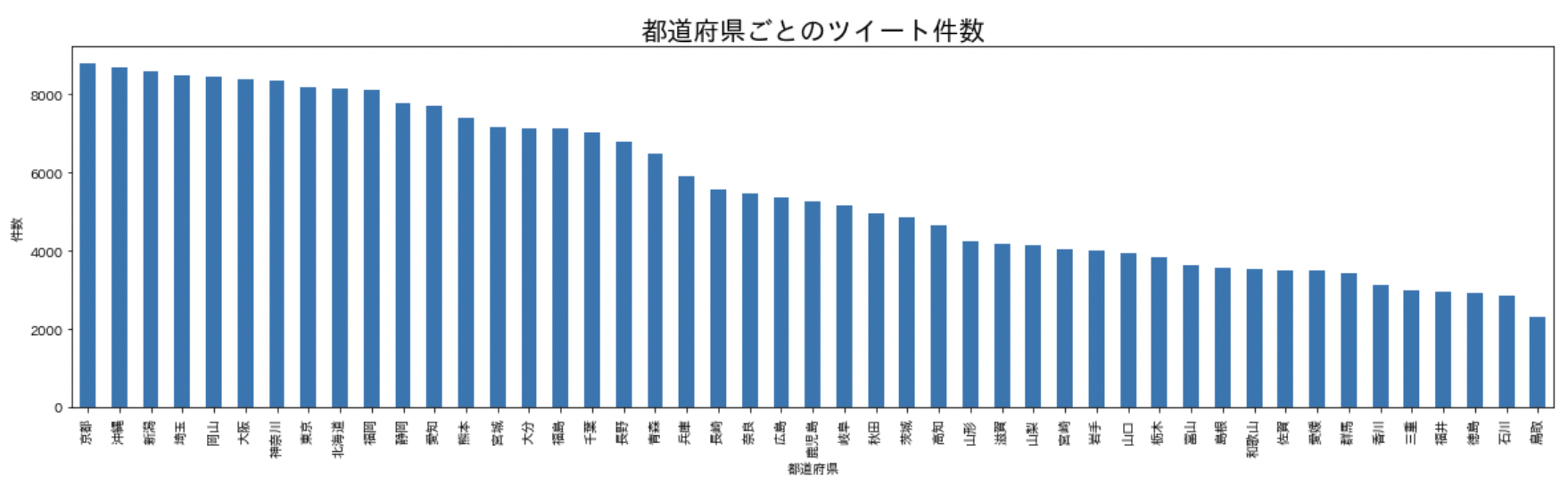
これを学習データとして都道府県を予測します。
分析結果
実際に上記の方法で各都道府県の類似度を上から並べてみた結果です。(ここでは予測確率が類似度を表します。)
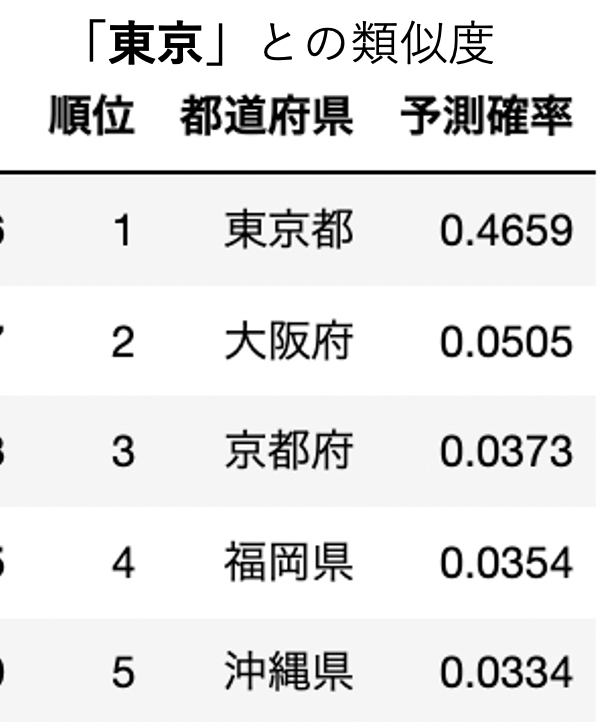
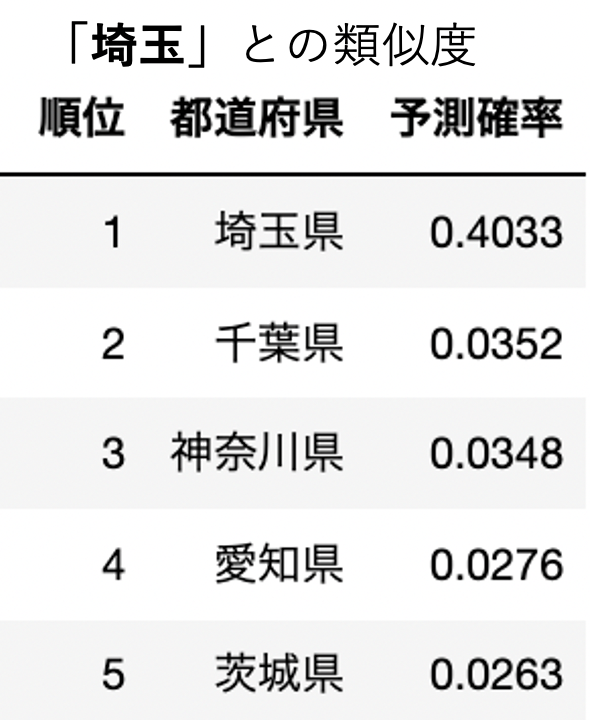
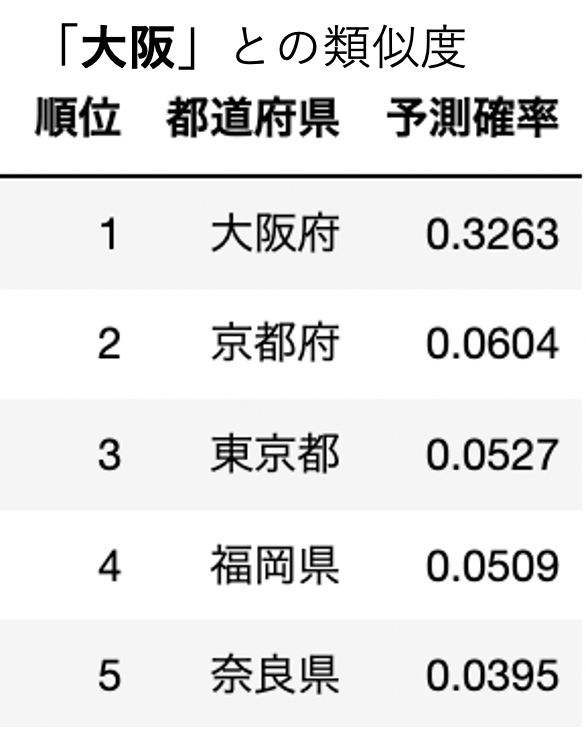
なんとなく似ている県が算出されていますね。うまくいってそうでしょうか?
佐賀に近い関東の都道府県
さて、それでは佐賀と類似度が高い関東の都道府県を出してみましょう。
関東で絞った結果はこちら。
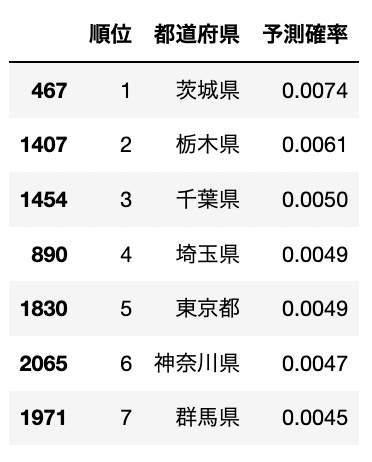
僅差ではありますが、佐賀は関東でいう茨城みたいです。
佐賀を茨城と予測した確率上位のツイートを見てみます。(本来は■に佐賀と入っているが、関東に絞った場合に茨城と予測しているツイートです。)

「■空港」、関東で■に入るのは茨城しかない気がしますね。
工業系高校も茨城が多いのでしょうか?
同じ佐賀を茨城と予測した他のツイートも見てみます。

方言の話題とか、農作物の話題がありますね。ここら辺から、モデルは似ていると判断していそうです。
都道府県の2次元plot
最後に、各都道府県の予測確率からMDSを使って2次元でplotしてみます。
使用した距離行列は各都道府県の予測確率行列に対して転置行列との平均をとって対称行列にして、 それを分母に持ってきた値です。
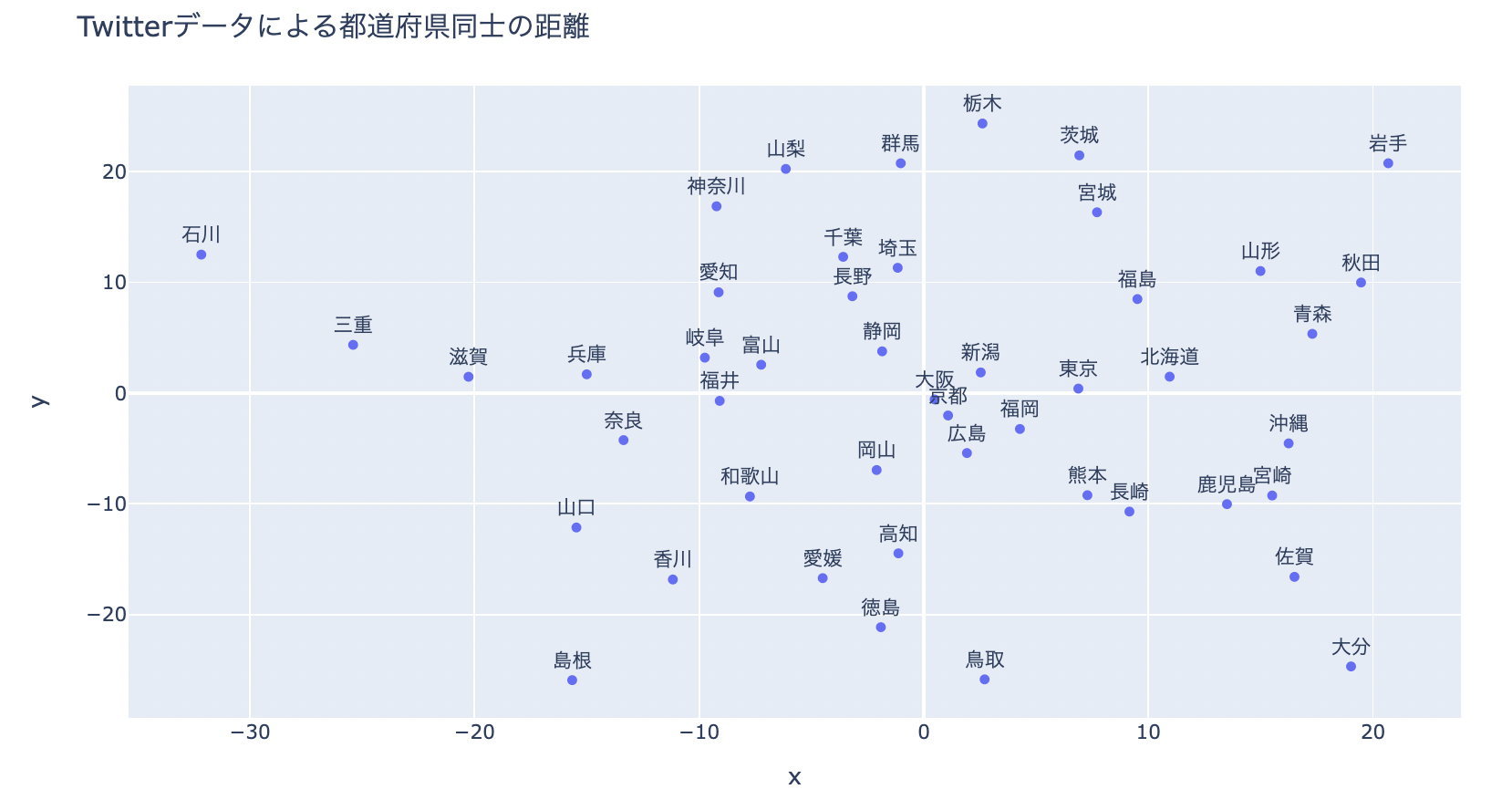
縦軸、横軸には意味はなく、距離が近い都道府県は互いの都道府県の予測確率が高く、類似度が高いといえます。
plotしてみると地域ごとにまとまっていますが、地域の中でも大阪-京都であったり、千葉-埼玉が近いのがわかります。
おわりに
今回は少し変わった分析をしてみました。
今後もちょっとした分析をブログで紹介していこうかなと思います。