BERTとshapでポジネガ分析の結果を解釈する
BERTと説明可能性
分析者としてお客さんに説明する際、結果だけでなく、なぜその結果になったのかという分析が求められることがよくあります。
しかし、BERTのようなDeep Learning手法では、一般になぜこの結果になったのかを出すことは難しいです。
BERTとは?という方は以前のブログを見てください。
BERTでは一応Attentionの可視化によって説明できなくはないですが、 Attentionはたくさんあってどれをみて良いかわからない、 ポジ、ネガどちらに効いているのかわからないなど、解釈としてはあまり適していないと私は考えています。
一方、近年ちょくちょく話題になる「shap」という機械学習のモデルを解釈する手法があります。
shapについては、以下のブログがわかりやすかったので貼っておきます。
https://dropout009.hatenablog.com/entry/2019/11/20/091450
tree系で使用しているcaseをよく見ますが、真価を発揮するのはブラックボックスになりがちなdeep learning系では?と思い、 BERTとshapを使って、ポジネガ分析の説明可能性を検証してみました。
BERTとshapの準備
今回動かしたコードはgithubに置いてありますので、適宜参考にしてください。
もし重くて開けない、画像が切れているなどありましたら、以下のリポジトリをダウンロードして、「BERT_shap.html」をみてください。
ポジネガ分析のモデルとしては、以前のブログのデータを少し変えたものを使用しました。
例の如く、yahoo locoのデータを用いています。

shapのbase valueが極端な値を取らないように、ポジネガそれぞれ2000件ずつをtrain_dataとしました。
BERTにおけるshap
shapを使うためのコードを解説します。
shapの実装には以下のブログを参考にしました。
https://qiita.com/m__k/items/87cf3e4acf414408bfed
まずは、shapのインスタンスを作成します。
modelにはテキストを入力して予測値を出力する関数を指定します。
maskerにはmodelに使用したBERTのtokenizerを指定します。
import shap
def f(X_test):
pred_probas = []
test_ds = ReviewDataset(texts=X_test)
test_dl = torch.utils.data.DataLoader(test_ds, batch_size=4, shuffle=False)
for input_ids, segment_ids, attention_masks in test_dl:
if cuda:
input_ids, segment_ids, attention_masks = input_ids.cuda(), segment_ids.cuda(), attention_masks.cuda()
outputs = model(input_ids = input_ids)
pred_probas.append(outputs.softmax(dim=1)[:,1].detach().cpu().numpy())
return np.concatenate(pred_probas)
# SHAP値を計算するインスタンスを生成する
explainer = shap.Explainer(model=f, masker=tokenizer)
shap valueの可視化1
実際に、shap valueを可視化してみます。
X_test = ["今日のランチは最高だった!","今日のランチは微妙だった"] shap_values = explainer(X_test) shap.plots.text(shap_values)
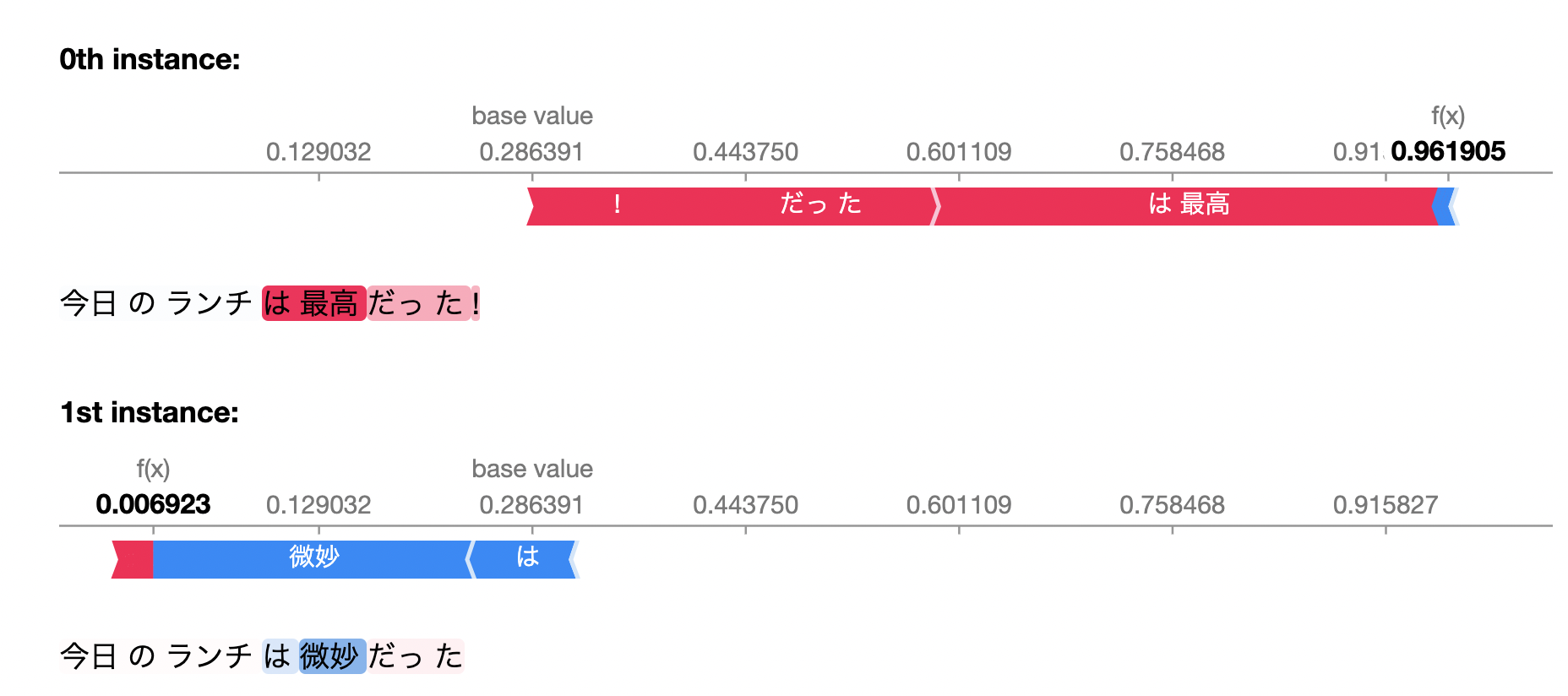
f(x)が予測値で、base valueがデータ全体の期待値です。
shapは、個々のデータについて、どの特徴量がプラス、マイナスに働いたかを表示することができます。
たとえば、「今日のランチは最高だった!」は全体の期待値よりも高めに予測をし、 「は最高」の部分がプラスに働いていると解釈できます。
反対に、「今日のランチは微妙だった」では、全体の期待値よりも低めに予測し、 「は微妙」の部分がマイナスに働いていることがわかります。
めっちゃわかりやすくないですか?自分が見たときは結構感動しました。
Deep Learningはブラックボックスになりがちだけど、 どこが効いているか、解釈を出すことができるかできないかで全然違う気がします。
shap valueの可視化2
次に、yahoo locoのvalidationデータで面白いと思ったshapの結果を紹介します。
1. 前半部は褒めているのでプラス、後半は大量に飲んだからお金がよりかかったということでマイナスに判定されています。

2. 前半部は美味しくないというのでマイナスですが、後半はボリュームやリッチについて書かれていてプラスに判定されていて最終的にはプラスになっています。

githubのコードでは、shap valueの例をたくさん出しているので、 より気になる方はみてみてください!
shap valueによる変数重要度
最後に、shap valueによる変数重要度を表示します。
shap.plots.bar(shap_values_Xval.mean(0), max_display=100)
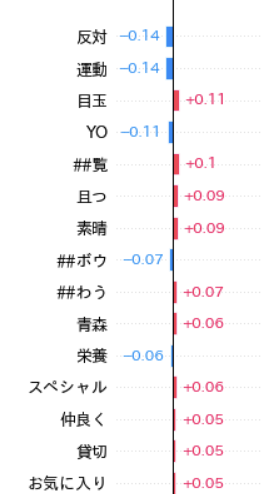
解釈は難しいですが、目玉、素晴、スペシャル、お気に入りなどはポジティブに影響していそうですね。
終わりに
shapについてはまだまだ勉強不足なので、どのモデルに適用するのが妥当か、ちゃんとした解釈や、 中身などは勉強したいと思っています。
ただ、shapの結果は見るだけで結構面白いので、一度試してみるのはありかなと思っています。
みなさんもぜひshap、使ってみてください!
Comments
Loading comments...